
服务热线热线:
0871-63910365
0871-63910365
 发布时间:2025-06-04
发布时间:2025-06-04 点击次数:
点击次数: 在当今科技飞速发展的时代,多模态大模型正成为人工智能技术探索的新前沿。这一领域汇聚了众多行业巨头与创新企业,如阿里巴巴、百度、腾讯等,它们不仅在各自的业务领域内深耕细作,更在多模态大模型的研发上展开了激烈的角逐。
多模态大模型的探索之路并非一帆风顺,它要求在不同的模态领域实现技术突破,从视觉到音频,从图像到视频,再到3D模型,每一步都充满了挑战。然而,正是这些挑战激发了产业的创新活力。理想中的“Any-to-Any”大模型,如Google的Gemini、Codi-2等,虽然仍处于探索阶段,但它们为未来的技术发展指明了方向。
在图像模型领域,产业界已经积累了丰富的经验。从CLIP、Stable Diffusion到GAN等模型,再到Midjourney、DALL · E等应用,图像的理解和生成技术已经取得了显著的进步。如今,产业界正积极探索将Transformer大模型引入图像相关任务,试图建立统一视觉大模型,并与大语言模型进行更紧密的融合,如GLIP、SAM、GPT-V等成果,正是这一趋势的体现。
视频模型作为图像模型的延伸,也取得了令人瞩目的进展。由于视频本质上是由多帧图像组成,因此图像生成模型的技术可以迁移到视频生成。近年来,VideoLDM、W.A.L.T.等模型的出现,标志着视频生成技术迈出了重要的一步。特别是Sora模型,它在视频生成领域首次呈现出“智能涌现”的迹象,为未来的技术发展提供了新的可能。
在3D模型领域,产业界同样在积极探索。虽然相比图像和视频生成,3D模型生成技术还处于早期发展阶段,但GAN、自回归、Diffusion、VAE等模型在3D模型生成任务中的扩展已经取得了初步成果。3D数据表征、数据集和生成模型的不断完善,为3D应用的发展提供了坚实的基础。
音频模型方面,Transformer大模型的引入成功推动了语音技术的进一步发展。从Whisper large-v3到VALL-E等模型的出现,语音技术的泛化能力得到了显著提升。从单一语种到多语种和方言,从人声到自然声音和音乐,从简单语音识别或合成到零样本学习和多任务集成,语音技术的应用范围不断扩大。
Omni模型作为音频模型的一个重要成果,它利用neural audio codec对音频进行编码以实现音频合成。通过embedding和adapter对文本和声波进行编码,再通过Omni模型进行合成和预测音频的token,最后通过扩散模型进行训练和解码器合成音频,这一过程展示了音频技术的最新进展。
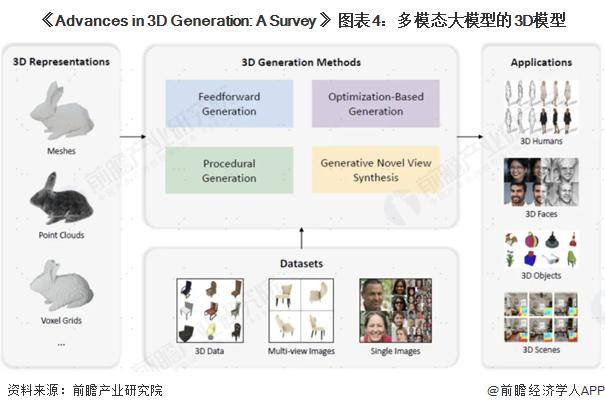
多模态大模型的探索正在逐步取得进展,从图像到视频,再到3D模型和音频模型,每一步都充满了创新与挑战。未来,随着技术的不断发展,多模态大模型将在更多领域发挥重要作用,为人类社会带来更多的便利和惊喜。
2025年半导体市场展望:WSTS预测规模将破7000亿美元,增长超一成
新榜讯 36氪消息,5月31日,敦煌研究院官宣“数字藏经洞”数据库平台正式上线多幅图像的数字化版本与全球用户实现“零接触”,其内容包含佛经、律典、契约、绢画等。…
明略科技Agent Show启航,探索AI超级助手如何赋能企业数智化转型
上汽奥迪双品牌发力,燃油车搭华为智驾,纯电E5 Sportback 3.4秒破百亮相
华为nova 14系列震撼登场!鸿蒙5直板机领衔,nova 14仅售2699元起
华为nova14 Ultra震撼登场!鸿蒙5系统加持,售价4199元起
2025年半导体市场展望:WSTS预测规模将破7000亿美元,增长超一成
本网站LOGO小熊标志受版权保护,版权登记号:鲁作登字-2015-F-025467,未经ITBEAR官方许可,严禁使用。Kaiyun网站Kaiyun网站

 当前位置:
当前位置:  上一篇:
上一篇: 返回列表
返回列表
